Mechanismus des Suchranking -Displays
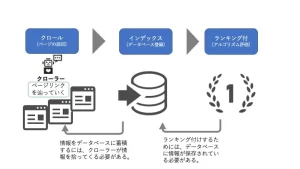
Lassen Sie uns vor der Erklärung des Crawlers einfach den Fluss der Informationen im Internet niederhalten und anzeigen.
Der Mechanismus mit der Rangliste der Suchmaschine ist, dass der Crawler alle Informationen im Internet, Indexes (Datenbankregistrierung) und die registrierten Daten mit einem Ranking (Algorithmus -Bewertung) erfasst. Mit anderen Worten, es ist erforderlich, verschiedene Informationen als Index (Datenbankregistrierung) zu speichern, um ein Rang zu bringen, und um zu indexieren, dass Crawl erforderlich ist. Das Programm, das Informationen aufnimmt, wird als Crawler bezeichnet. wie hart Sie arbeiten und Inhalte erstellen , es wird in den Suchergebnissen nicht angezeigt.
Was macht der Crawler?
Der Crawler führt eine "Analyse (Perhaling)" durch, wenn Sie die Seite erreichen.
"Analyse" bedeutet, die Seiteninformationen so zu verarbeiten, dass der Algorithmus leicht zu verstehen ist und in der Datenbank registriert. Als Teil davon werden wir einen Link auf der Seite finden und mit den Seiten nacheinander fortfahren.
-Das Dateikrallenziel
des Kriechlings ist wie folgt vielfältig, und die meisten Informationen im Web werden vom Crawler gesammelt.
・ HTML -Datei
・ CSS -Datei
・ JavaScript -Datei
・ Bild
・ Flash
・ PDF
-Crawler -Typ
hat auch eine Art von Crawler, und für jede Suchmaschine stehen Programme zur Verfügung. Darüber hinaus gibt es verschiedene Crawler, die Crawler -Dienste entwickeln.
GoogleBot (Google)
, Bingbot (Bing betrieben von Microsoft)
, Yahoo Slurp (Yahoo! Außer Japan)
, Baiduspider (chinesische Suchstelle Baidu)
, Yetibot (Korea Major Such Site Naver)
Die Bedeutung der Kriechlichkeit bei Crawl -Maßnahmen
Obwohl zwischen den einzelnen Standorten einen Skalenunterschied besteht, gibt es zig Millionen von Seiten im Internet. Unter solchen Umständen kann die Anzahl der Crawler patrooliert werden. Wenn Sie beurteilen, dass Crawls nicht erforderlich sind, wird die Häufigkeit von Crawls reduziert, um Abfall zu verhindern.
・ Websites, deren Websites kontinuierlich aktualisiert werden oder
die Aktualisierung gestoppt haben, werden beurteilt, dass keine Krabben erforderlich sind.
・ Es gibt eine Nachfrage nach Websites, und
selbst wenn die Update -Frequenz nicht so hoch ist, werden Websites, die von vielen Benutzern verwendet werden, ordnungsgemäß gekrabbt.
Wenn Sie sich auf SEO -Maßnahmen konzentrieren, denke ich, dass wir uns bereits auf kontinuierliche Aktualisierungen der oben genannten Standorte und die Produktion solider Inhalte konzentrieren. Was soll ich also tun, um das erstellte Seitenkriechen und den Index zu erhalten? Dazu ist es notwendig, die Kriechlichkeit zu verbessern. Crawbability bedeutet, dass der Crawler leichter Seiten zu finden ist und die Website ausdrückt, um Crawlers zu erleichtern, die Informationen auf der Website zu entschlüsseln.
Um einen Crawler eine hohe Frequenz zu haben,
werde ich speziell erklären, welche Seiten und Websites hoch sind.
・ Durch Anhängen der internen Link an die zugehörigen Hochseiten
sind die verknüpften Seiten mit den zugehörigen Seiten verknüpft, damit der Crawler für jede Seite erkannt werden kann. Zu diesem Zeitpunkt ist die Relevanz mit dem Schlüsselwort einfacher zu verstehen, indem es einen einfachen Linknamen für den -verständlichen Link macht.
・ Wenn die URL verwendet wird, um eine Brotkrümelliste festzulegen und die Seitenhierarchie
kompliziert ist, ist es eine Site, die für Crawler schwierig ist, und die Effizienz wird reduziert. Richten Sie eine Punk -Slist ein, um es dem Crawler zu erleichtern, die Struktur der Website zu erfassen. <Klicken Sie hier, um die Liste der Brotkrümel zu setzen>
-Die wichtige Seiten, die die URL -Hierarchie flach machen,
folgen der internen Verbindung, sodass die Seiten mit flachen Links einfacher zum Crawler verteilt werden können.
Wenn der Link tiefer wird, kann sich der Crawler die Zeit nehmen, um die Seite zu finden.
・ Crawler, der die Textkonfiguration markiert,
versteht den Inhalt des Textes nicht, während wir lesen. Sie können die Seitenkonfiguration vermitteln, indem Sie die Konfiguration der Seite markieren, z. B. Überschriften und Absätze mit einem HTML -Tag.
HTML kann als <elementnamensattributs = "Attributwert"> festgelegt werden,
und es ist leicht zu verstehen, ob Sie ihn durch den Crawler ersetzen, z. B. "Das Attribut des Elementnamens ist der Attributwert".

Wenn
beispielsweise
IMG (Bild eingebettetes Element), SCR (Attribut), Attributwert (URL des verwendeten Bilds) oder Alt ist ist die SCR (Informationsquelle) von IMG (Bildgebung) "URL" und ALT (IMG). Die Erklärung des Elements).
Sie neigen dazu, ein ALT -Tag festzulegen, mit dem Bilder und Abbildungen auf der Seite an den Crawler vermittelt werden. Lassen Sie uns die feinen Tags fest einsetzen.
< Klicken Sie hier, um HTML -Tags zu schreiben >
・ Vorbereitung von XML -Site -Karten für Crawler
Es gibt zwei Arten von Site -Karten. Es gibt eine XML -Site -Karte, auf der die erforderlichen Informationen im Crawler leicht zu verstanden werden. Durch die Erstellung einer XML -Site -Karte
können Sie dem Crawler verschiedene Site -Informationen übermitteln.
・ Teilen Sie das letzte Aktualisierungsdatum der Seite mit
・
Frequenz von Seite Update
・ Sagen Sie die Priorität für die Seite
・ Troller, die die Existenz von Seiten mit wenigen internen Links vermittelt Über die Frequenz gesprochen, aber durch die Erstellung einer XML -Site -Karte können Sie die Aktualisierungsinformationen ordnungsgemäß übermitteln. ▼ Verwandter Artikel
< Über das Einstellen von XML -Site -Karte > < Empfohlener Plug -Inin >
Große Stellen benötigen Maßnahmen! Über Crawl -Budget
Bis jetzt haben wir die Bedeutung von Kriechen erklärt, aber es bedeutet nicht, dass alle Seiten alle gekrabbt werden. Haben Sie jemals das Wort Crawl Budget gehört?
Ein Crawl -Budget ist die Obergrenze eines Crawlers, mit dem Sie die Seite patrouillieren können.
Budget = Budget, aber es wird nicht verwirrt, wenn Sie erfahren, dass es im Voraus eine feste Nummer wie ein Budget als Budget gibt. Wenn Sie über die Crawl -Budgets hinausgehen, können Crawler die Zielseite nicht kriechen, sodass Sie Crawls optimieren müssen.
Es gibt jedoch nicht viel, um eine solche Obergrenze zu erreichen, sodass Sie sich außer Zehntausenden von Seiten nicht zu viel Sorgen machen müssen.
Die folgenden Fälle, in denen Google die Obergrenze berücksichtigen sollte, ist wie folgt.
・ Wagenseiten (1 Million Seiten oder mehr), wenn die Inhaltsaktualisierungen (einmal pro Woche)
・ Websites über mittelgroße oder mehr (10.000 Seiten oder mehr) sind, ist der Inhalt schnell (täglich). Wenn es geändert wird
, ist es möglich, komplexe Suchvorgänge wie Immobilienstandorte und E -Commerce -Websites durchzuführen. Wenn Sie Parameter in der URL jedes Suchergebnisses oder der Produktnummer nur vom Betrieb der EC -Site festlegen Sie haben eine große Menge an URL, Sie müssen vorsichtig sein, wenn Sie eine separate URL auf einer Smartphone -Website und auf einer PC -Site haben. Obwohl der Seiteninhalt gleich ist, gibt es mehrere URLs. Wenn Sie sie also nicht verwalten, gibt es Probleme, die auf der Seite, die Sie bewerten möchten, nicht stabil krabbeln.
Wenn Sie Crawls verwalten möchten und wie man sich ablehnt
Neben der Überlegung von Crawl -Budgets,
wenn Sie Ihr eigenes Engagement beibehalten möchten oder wenn Sie sie als eine Website behalten möchten, die von geringer Qualität ist, oder als Seite mit geringer Relevanz für die Website.
Manchmal ist es besser, Krabben zu verweigern Während des Tests oder beim Einstellen Bitte beachten Sie einige Methoden.
Verwalten Sie Linkeinheiten mit Nofollow
Nofollow ist der Wert, der festgelegt ist, wenn Sie vermeiden möchten, dem verknüpften Link zu folgen. Empfohlen, wenn Sie einen unnötigen Zusammenhang unter Berücksichtigung von Crawl -Budgets herstellen.
Mit dem REL -Attribut des Ankerelements (einem Element) können bestimmte Links nicht angehalten werden.
(Beispiel) Wenn Sie den A -Site -Link von "Ich empfehle diesmal ein -Ort".
"Dieses Mal empfehlen wir
auch
Müll ohne NoIndex
NoIndex ist eine Art Meta -Element, und wenn diese Beschreibung nicht ist, registriert der Crawler den Index nicht. Unabhängig davon, ob andere Websites mit dieser Seite verknüpft sind, wird die Seite vollständig aus den Google -Suchergebnissen gelöscht.
Verwenden Sie es, wenn Sie die Anzeige aus dem Suchergebnis selbst beseitigen möchten, nicht das Linkmanagement.
Bitte beschreiben Sie es im Abschnitt Abschnitt Betreff wie folgt.
・ Wenn Sie den Crawler der meisten Suchmaschinen blockieren möchten
・ Wenn Sie GoogleBot blockieren möchten
<Kommentar zu Meta -Elementen>
Hinweis! Gibt es einen Fall, in dem er indiziert werden sollte, obwohl er hätte festgelegt werden sollen? !
Legen Sie den Robots.txt nicht fest, eine der nächsten auf der NoIndex -Einstellungsseite beschriebenen der nächsten Klauen -Ablehnungsmethoden.
Wenn Robots.txt auf der Seite "NoIndex" festgelegt ist, erkennt der Crawler möglicherweise nicht die NoIndex -Anweisung, aber der Link von anderen Seiten wird die Seite angezeigt.
Ich werde erklären, warum so etwas passiert und der Mechanismus von Robots.txt.
Müll mit Robots.txt
So erstellen Sie eine Robots.txt -Datei und laden Sie sie auf die Website hoch. Wie Nofollow ist es ein effektives Mittel für Seiten, die Sie nicht kriechen möchten.
Im Gegensatz zu Nofollow, das sich weigert, dem Link zu folgen, ist Robots.txt eine Methode, um einen Crawler selbst für einen bestimmten Pfad oder eine bestimmte Datei abzulehnen.
Wenn Sie den Robots.txt festlegen, bevor die NoIndex -Einstellungen erkannt werden, erkennt der Crawler die auf der Seite festgelegten NoIndex -Einstellungen nicht.
Infolgedessen wird es weiterhin aus dem internen Link einer anderen Seite indiziert.
In einem solchen Fall wird eine Warnung, die "von Robots.txt blockiert wurde, jedoch im Index registriert wurde" in der Suchkonsole angezeigt, sodass Google die NoIndex -Einstellung erkennt (auch wenn Sie suchen, die Seite ist die Seite. Überprüfen Sie Robots.txt. Überprüfen Sie Robots.txt. nach bestätigten, dass es nicht herauskommt).
<Offiziell: So erstellen Sie eine Robots.txt -Datei >
Selbst wenn Sie NOIndex oder Robots.txt festlegen, können Sie die Seite durch die Ziele einbrocken, um die Zielseite zu bearbeiten.
Wenn Sie nicht krabbelt werden möchten, z. B. eine Seite in der Entwicklung, oder wenn Sie nicht möchten, dass Benutzer auf die Seite zugreifen, wenden Sie ein Passwort an.
Als nächstes werden wir vorstellen, wie Sie den Crawler -Zugriff und den Benutzerzugriff einschränken.
Mit .htaccess ablehnen
.htaccess ist eine Datei, die einen Webserver konfigurieren und steuern kann, der die Software "Apache" in einem Verzeichnis verwendet. Sie können eine Weiterleitung festlegen und es ermöglichen, nur eine bestimmte IP -Adresse herzustellen. Eine davon besteht darin, der grundlegenden Authentifizierungsstelle ID und Kennwortauthentifizierung hinzuzufügen. Wenn Sie eine grundlegende Authentifizierung festlegen, kann der Crawler nicht auf die Website zugreifen. Die grundlegende Authentifizierungseinstellung kann festgelegt werden, indem die Datei .htaccess und das Hochladen auf den Server wie die Robots.txt -Datei hochgeladen wird.
Wenn Sie den Crawler oder Benutzer nicht durchlaufen möchten, legen Sie die grundlegende Authentifizierung fest.
<Klicken Sie hier, um eine ausführliche Erläuterung der grundlegenden Authentifizierung
*

Der SEO -Stil erhält kostenlose Diagnose und Beratung auf der Website
Diesmal erklärte ich über Crawl -Maßnahmen. SEO -Maßnahmen sind nicht nur die Qualität des Inhalts, sondern auch die technischen technischen SEOs.
Diese technischen Teile haben jedoch mehr IT -Begriffe, und es kann schwierig sein, Maßnahmen zu untersuchen und Maßnahmen zu ergreifen. In einem solchen Fall wenden Sie sich bitte an den SEO -Stil. Wir werden ein Standortproblem aus der Standortdiagnose starten und eine geeignete Lösung vorschlagen. <Anquiries>













![[Kernaktualisierung von Mai 2022] Google kündigt das erste Kern -Update im Jahr 2022 an!](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/23628486_s-75x75.jpg)
![[Site -Betreiber muss sehen] Was hat den Rangranking -Rückgang verursacht? Wie löste ich den Strafe Typ frei und wie kann ich ihn stornieren?](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/4925517_s-75x75.jpeg)
![[November 2021 Lokales Suchaktualisierung] Lokale Suchaktualisierung](https://www.seostyle.net/esuio4587/wp-content/uploads/2021/12/5002701_s-1-75x75.jpeg)






