Механизм показателя рейтинга
Перед объяснением гусеницы давайте просто удержим поток информации в Интернете и отобразим ее.
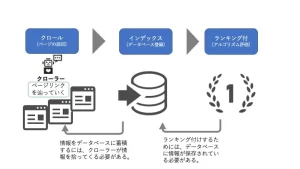
Механизм с ранжированием поисковой системы состоит в том, что Crawler собирает всю информацию в Интернете, индексы (регистрация базы данных), а зарегистрированные данные с рейтингом (оценка алгоритма). Другими словами, необходимо хранить различную информацию в качестве индекса (регистрация базы данных), которая должна быть ранжирована, и индексировать ее требует ползания. Программа, которая собирает информацию, называется гусеницей. , насколько усердно вы работаете и создаете контент , он не будет отображаться в результатах поиска.
Что занимается гусеницей?
Груплер выполняет «Анализ (перчастинг)», когда вы достигаете страницы.
«Анализ» означает обработку информации о странице, чтобы алгоритм был просты для понимания и регистрируется в базе данных. В рамках этого мы найдем ссылку на странице и продолжим на страницах один за другим.
-Цель когтиков файла
для ползания разнообразна, и большая часть информации в Интернете собирается Crawler.
・ HTML -файл
・ CSS Файл
・ файл JavaScript
・ Изображение
・ Flash
・ PDF
-Crowler Тип
также имеет тип Crawler, и программы доступны для каждой поисковой системы. В дополнение к этому, существуют различные сканеры, которые разрабатывают сервисы Crawler.
Googlebot (Google)
, Bingbot (Bing, управляемый Microsoft)
, Yahoo Slurp (Yahoo!, кроме Японии)
, Baiduspider (китайский сайт поиска Baidu)
, Yetibot (Korea Maue Search Site Naver)
Важность полной поверхности в мерах ползания
Хотя между каждым сайтом существует разница в масштабе, в Интернете есть десятки миллионов страниц. При таких обстоятельствах число сканеров может быть патрулировано. Поэтому, если вы судите, что ползание не нужны, частота ползания будет уменьшена, чтобы предотвратить отходы.
・ Сайты, сайты которых постоянно обновляются или
перестают обновлять, будут признаны, что нет необходимости в ползаниях.
・ Существует спрос на сайты, и
даже если частота обновления не так высока, сайты, используемые многими пользователями, правильно ползают.
Если вы сосредотачиваетесь на показателях SEO, я думаю, что мы уже сосредотачиваемся на непрерывных обновлениях вышеуказанных сайтов и производстве твердого контента. Итак, что я должен сделать, чтобы получить созданную страницу Crawl and Index? Для этого необходимо улучшить ползуемость. Ползание означает , что гусеницу легче найти страницы, и выражает веб -сайт, чтобы упростить сканеры расшифровать информацию на веб -сайте.
Чтобы иметь гусеница высокой частоты,
я специально объясню, какие страницы и сайты высоки.
・ Подключив внутреннюю ссылку к соответствующим высоким страницам,
связанные страницы связаны с соответствующими страницами, чтобы гусеницы можно было распознавать для каждой страницы. В то время, делая его легким -понять имя ссылки, актуальность с ключевым словом легче понять.
・ Если URL используется для установления списка панировочных крошек, а иерархия страницы
сложна, это будет сайт, который будет трудно понять, и эффективность будет снижена. Установите панк -стлистскую службу, чтобы утолкнул для хлистого, чтобы понять структуру сайта. <Нажмите здесь для настройки списка хлебных крошек>
-Важные страницы, которые делают URL -иерархию мелкой,
следуют внутренней ссылке, поэтому страницам легче распространять мелкие звень
Если ссылка становится глубже, гусеница может потратить время, чтобы найти страницу.
・ Crawler, который отмечает текстовую конфигурацию,
не понимает содержимое текста, как мы читаем. Вы можете передать конфигурацию страницы, отметив конфигурацию страницы, такую как заголовки и абзацы с помощью HTML -тега.
HTML может быть установлен как <at attrubute = "attribute">,
и легко понять, если вы замените его на Crawler, такой как «атрибут имени элемента - значение атрибута».
Например,

если
IMG (встроенный элемент изображения), SCR (атрибут), значение атрибута (URL используемого изображения) или ALT SCR (источник информации) IMG (Imaging) является «URL» и Alt (IMG). Объяснение элемента).
Вы, как правило, забываете установить Alt -тег, который передает изображения и иллюстрации на странице на Crawler. Давайте твердо поместим тонкие теги.
< Нажмите здесь, чтобы написать теги HTML >
・ Подготовка карт сайта XML для Crawler
Существует два типа карт сайта: HTML -карты для передачи информации о сайте легко -понятно, чтобы пользователи могли легко добраться до желаемой страницы. Существует карта сайта XML, которая легко передает необходимую информацию в Crawler легко -понятным образом. Подготовив карту сайта XML, вы
можете передать различную информацию о сайте Crawler.
・ Расскажите о последней дате обновления страницы
・ Сделайте частоту обновления страницы
・ Скажите приоритет на странице
・ Troller, который передает существование страниц с несколькими внутренними ссылками,
если сайт не обновляется, это ползает, чтобы предотвратить отходы Рассматривая о частоте, но, подготовив карту сайта XML, вы можете правильно передать информацию об обновлении.
▼ Связанная статья
< О настройке карты сайта XML > < Рекомендуемый плагин -IN >
Крупные сайты требуют мер! О бюджете ползания
До сих пор мы объясняли важность ползания, но это не означает, что все страницы заползли. Вы когда -нибудь слышали слово бюджет скала?
Бюджет для полза является верхним пределом гусеницы, который позволяет патрулировать страницу.
Бюджет = бюджет, но он не запутывается, если вы узнаете, что есть фиксированное число заранее, например, бюджет, как бюджет. Если вы выйдете за рамки бюджетов Crawl, Crawlers не смогут ползти страницы сайта целевого сайта, поэтому вам нужно оптимизировать ползание.
Тем не менее, не так много, чтобы достичь такого верхнего предела, поэтому вам не нужно слишком беспокоиться о ползании, за исключением десятков тысяч страниц.
Следующие случаи, когда Google должен учитывать верхний предел, заключается в следующем.
・ Крупные сайты (1 миллион страниц или более), когда обновления контента умеренные (один раз в неделю)
・ сайты по среднему размеру или более (10 000 страниц или более), контент быстрый (ежедневно). Если он изменен
, можно выполнить сложные поиски, такие как сайты недвижимости и E -Commerce, и если вы устанавливаете параметры в URL -адресу каждого результата поиска, или номер продукта только в зависимости от работы сайта EC У вас есть большое количество URL, вы должны быть осторожны, если у вас есть отдельный URL на сайте смартфона и сайт ПК. Хотя содержимое страницы одинаково, существует несколько URL -адресов, поэтому, если вы не управляете ими, будут проблемы, которые не будут стабильно заполняться на странице, которую вы хотите оценить.
Если вы хотите управлять ползаниями и как отказаться
В дополнение к рассмотрению бюджетов для полки,
если вы хотите сохранить свое собственное обязательство, или если вы хотите сохранить его как сайт с низким качеством, или страницу с низкой релевантностью для сайта.
Иногда лучше отказаться от ползания во время тестирования или при корректировке Пожалуйста, обратитесь к некоторым методам.
Управлять единицами ссылки с Nofollow
Nofollow - это значение для установки, если вы хотите избежать следующей ссылки. Рекомендуется при принятии ненужного звена с учетом бюджетов Crawl.
Нофоллоу конкретных ссылок можно сделать с атрибутом REL элемента якоря (элемент).
(Пример) Если вы хотите использовать ссылку A -Site «Я рекомендую на этот раз».
этот раз мы рекомендуем -site».
Отказаться от noindex
NoIndex - это тип мета -элемента, а когда это описание не является, Clawler не регистрирует индекс. Независимо от того, связаны ли другие сайты с этой страницей, страница полностью удалена из результатов поиска Google.
Используйте его, когда вы хотите исключить дисплей из самого результата поиска, а не управления ссылками.
Пожалуйста, опишите это в разделе субъекта следующим образом.
・ Если вы хотите заблокировать гусеница большинства поисковых систем
・ Если вы хотите заблокировать Googlebot
<Комментарий к мета -элементам>
Примечание! Есть ли случай, когда он должен быть проиндексирован, даже если он должен был быть установлен? !
Не устанавливайте robots.txt, один из следующих методов отклонения когтя, описанных на странице настройки NoIndex.
Если robots.txt установлен на странице Setex Set, Crawler может не распознать директиву noindex, но ссылка с других страниц будет отображаться.
Я объясню, почему такая вещь происходит и механизм роботов.txt.
Отказаться от robots.txt
Как подготовить файл robots.txt и загрузить его на сайт. Как и Nofollow, это эффективное средство для страниц, которые вы не хотите ползать.
В отличие от Nofollow, которая отказывается перейти по ссылке, robots.txt - это метод отказа от самого гусеница для определенного пути или файла.
Поэтому, если вы установите robots.txt до того, как настройки NoIndex будут распознаваться, Crawler не распознает настройки NoIndex, установленные на странице.
В результате он будет по -прежнему индексировать по внутренней ссылке другой страницы.
В таком случае в консоли поиска появилось предупреждение о том, что «было заблокировано robots.txt, но зарегистрировано в индексе», поэтому Google распознает настройку noindex (даже если вы ищете, страница - это страница. Проверьте robots.txt После подтверждения, что это не выйдет).
<Официально: как создать файл robots.txt >
, даже если вы устанавливаете NoIndex или установите robots.txt, если пользователь застряет на целевой странице, чтобы работать над Crawler.
Если вы не хотите, чтобы вас ползали, например, на разработанной странице, или если вы не хотите, чтобы пользователи получали доступ к странице, примените пароль.
Далее мы представим, как ограничить доступ к Crawler и доступ пользователя.
Отвергай с .htaccess
.htaccess - это файл, который может настроить и управлять веб -сервером, который использует программное обеспечение, называемое «Apache» в каталоге. Вы можете установить перенаправление, позволяя подключаться только к определенному IP -адресу. Одним из них является добавление идентификационной аутентификации и аутентификации пароля к основному сайту аутентификации. Если вы установите базовую аутентификацию, Crawler не сможет получить доступ к сайту. Основная настройка аутентификации может быть установлена путем подготовки файла .htaccess и загрузив его на сервер, например, файл robots.txt.
Если вы не хотите проходить через Crawler или пользователя, установите основную аутентификацию.
<Нажмите здесь для подробного объяснения базовой аутентификации
*

SEO стиль получает бесплатную диагностику и консультации на сайте
На этот раз я объяснил о мерах ползания. Меры SEO - это не только качество содержания, но и такие технические SEO, поэтому давайте принять меры.
Тем не менее, эти технические детали имеют больше терминов ИТ, и может быть трудно изучать и принять меры. В таком случае обратитесь в SEO -стиль. Мы запустим проблему сайта из диагноза сайта и предложим соответствующее решение. <Запросы>













![[Обновление основного мая 2022 года] Google объявляет первое обновление Core в 2022 году!](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/23628486_s-75x75.jpg)
![[Оператор сайта должен увидеть] Что вызвало рейтинг? Как выпустить тип штрафа и как его отменить?](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/4925517_s-75x75.jpeg)
![[Ноябрь 2021 г. Обновление локального поиска] Обновление локального поиска](https://www.seostyle.net/esuio4587/wp-content/uploads/2021/12/5002701_s-1-75x75.jpeg)






