2022年5月12日技术SEO ,爬网对策, SEO措施,内部措施

什么是爬网错误?
我认为有些人可能不会听到很多有关爬网错误的消息,所以我将首先解释。
GoogleBot(Google crawler)无法爬网的页面,即无法确认的页面。
您是否曾经看到过带有搜索引擎的页面?
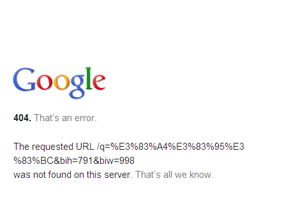
这是爬网错误状态。我经常看到404!
还有其他类型,但我稍后会解释。
仅仅因为这个爬网错误并没有急剧下降,但是Google也是“恶意的”,即使您不打算在您认为的情况下造成大量的爬网。
爬网的类型错误
爬网错误有两种主要类型。
…
爬网无法访问该
站点
一条消息出现在网站管理员工具中,因此您可以通过错误单击URL来检查原因。
主要原因
有一个状态代码可以显示原因。
有很多类型,但是我会选择常见的代码并介绍它们。
・404…没有要求的页面
・403…访问禁令
・503…暂时访问不可能
・ 400…非法请求
・ 408…超时
看着这一点,我觉得自己做错了什么,但是警告说:“我是一个错误,但是可以吗?
”在黑暗中不会因为有法律而在黑暗中删除它。
如何消除爬网错误
根据原因,有多种处理错误的方法,但是这次我们将介绍如何消除常见404错误。
404错误由于以前的说明中没有某种原因而没有页面。
我目前怀疑的第一件事是:“您是否更改网站的URL?”
例如,假设在“ 20150420brog.html”中将博客文章上传一次,并将其索引到爬网。 但是,在此之后,当我以为“哦,我在咒语中犯了一个错误”时,然后将名称更改为“ 20150420blog.html”,然后将其上传到“ 20150420brog.html”时,将其上传到搜索引擎时,此页是404错误。
有一个页面,但名称已更改,因此它将被视为不会是页面的页面...在这种情况下,我会很好地将其重定向,并告知Google已从“ 0150420Blog.html”更改。到“ 20150420 blog.html”。











![[2022年5月的核心更新] Google宣布了2022年的第一个核心更新!](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/23628486_s-75x75.jpg)
![[站点运营商必须看到]是什么原因导致排名下降?如何发布罚款类型以及如何取消罚款类型?](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/4925517_s-75x75.jpeg)
![[2021年11月本地搜索更新]本地搜索更新](https://www.seostyle.net/esuio4587/wp-content/uploads/2021/12/5002701_s-1-75x75.jpeg)






