搜索排名显示机理
在爬行者的解释之前,让我们简单地按住Internet上的信息流并显示。
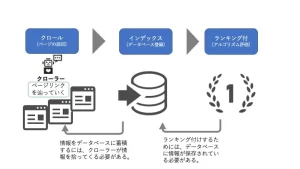
搜索引擎排名的机制是,爬网手在Internet上收集所有信息,索引(数据库注册),并且注册数据具有排名(算法评估)。换句话说,有必要将各种信息存储为要排名的索引(数据库注册),并需要索引它需要爬网。获取信息的程序称为爬网。您有多努力和创建内容,都不会在搜索结果中显示。
爬虫在做什么?
到达页面时,爬网行执行“分析(perhaling)”。
“分析”是指处理页面信息,以便该算法易于理解并在数据库中注册。作为其中的一部分,我们将在页面中找到一个链接,然后再逐步继续页面。
-
爬行的文件捕获目标的多样性如下,网络上的大多数信息都是由轨道收集的。
・ html文件
・ css文件
・ javaScript文件
・映像
・ flash
・ pdf
-crawler类型
还具有一种crawler,并且每个搜索引擎都可以使用程序。除此之外,还有许多正在开发爬网服务的爬行者。
GoogleBot(Google)
,Bingbot(Microsoft由Microsoft运营)
,Yahoo Slurp(日本以外的Yahoo!)
,Baiduspider(中国搜索网站Baidu)
,Yetibot(韩国主要的搜索网站NAVER)
爬网性在爬网措施中的重要性
尽管每个站点之间的规模都有差异,但互联网上有数千万页。在这种情况下,可以巡逻的爬行者数量。因此,如果您判断不需要爬网,则将减少爬行的频率以防止浪费。
・其站点不断更新或
停止更新的站点将被判断为无需爬网。
・有对网站的需求,
即使更新频率不那么高,许多用户使用的站点也适当地爬了。
如果您专注于SEO措施,我认为我们已经专注于上述站点的连续更新和固体内容的生产。那么,我该怎么做才能获得创建的页面爬网和索引?为此,有必要提高爬行性。爬网性意味着爬网更容易找到页面并表达网站,以使爬虫更容易在网站上解密信息。
要使爬网较高的频率,
我将专门说明哪些页面和站点很高。
・通过将内部链接连接到相关的高页面,
链接的页面链接到相关页面,以便可以为每个页面识别爬网。当时,通过使其简单地理解链接名称,与关键字的相关性更容易理解。
・如果URL用于设置面包屑列表,并且页面层次结构
很复杂,则将很难理解crawler的站点,并且效率将降低。建立一个朋克SLIST,以使爬虫更容易掌握站点的结构。 <单击此处以获取面包屑列表的设置>
- 使URL层次结构浅的重要页面
遵循内部链接,因此,具有浅链接的页面更容易将其传播到爬虫。
如果链接变得更深,则爬行者可能会花时间找到页面。
标记文本配置的crawler
在我们阅读时不了解文本的内容。您可以通过标记页面的配置,例如带有HTML标签的标题和段落来传达页面配置。
可以将HTML设置为<元素名称属性=“属性值”>,
如果将其替换为crawler,例如“元素名称的属性是属性值”,则很容易理解。
例如,

如果
IMG(Image Embedded元素),SCR(属性),属性值(所使用的图像的URL)或ALT 则IMG(Imaging)的SCR(Information Source)为“ url”和ALT(IMG)。元素的解释)。
您倾向于忘记设置一个Alt标签,该标签将页面中的图像和插图传达给爬网。让我们牢固地放入精美的标签。
<单击此处,以获取如何编写HTML标签>
・准备爬网XML站点地图,
有两种类型的站点地图,HTML Sitemaps可以简单地理解方式来传达该站点信息,以便用户可以轻松地到达所需的页面。有一个XML站点地图,以一种简单地理解的方式传达了爬行者中必要的信息。通过准备XML站点地图,您
可以将各种站点信息传达给爬虫。
・告诉页面的最后更新日期
・使页面更新频率
・说明页面的优先级
・拖钓者,该页面传达了几个页面的存在,
如果没有更新网站,则是爬网以防止浪费谈到了频率,但是通过准备XML站点地图,您可以正确传达更新信息。
▼相关文章
<关于设置XML网站映射> <推荐插头-in >
大型站点需要措施!关于爬网预算
到目前为止,我们已经解释了爬网的重要性,但这并不意味着所有页面都被爬了。您有没有听过爬网一词的预算?
爬网预算是爬网的上限,它允许您巡逻页面。
预算=预算,但是如果您得知提前有一个固定的数字,例如预算,那就不会感到困惑。如果您超越了爬网预算,则爬网将无法爬网,因此您需要优化爬网。
但是,没有太多要达到这样的上限,因此除了成千上万的页面外,您不必担心爬网太多。
Google应该考虑上限的以下情况如下。
・大型站点(100万页或更多),当内容更新中等(每周一次)
・地上米大型或更多(10,000页或更多页)时,内容很快(每天)。如果已更改
,则可以执行复杂的搜索,例如房地产网站和E -Commerce网站,如果您在每个搜索结果的URL中设置参数,或者仅根据EC网站的操作您有大量的URL,如果您在智能手机网站和PC网站上有单独的URL,则需要小心。尽管页面内容是相同的,但是有多个URL,因此,如果您不管理它们,那么您要评估的页面上会有稳定爬网的问题。
如果您想管理爬网以及如何拒绝
除了考虑爬网预算,
如果您想保留自己的承诺,或者要将其保留为低质量的网站,或与网站相关的页面。
在测试期间或调整时请参考一些方法。
用nofollow管理链接单元
如果要避免遵循链接的链接,则Nofollow是设置的值。考虑到不必要的链接时,建议考虑到抓取预算。
可以使用锚元素的RER属性(元素)进行特定链接的nofollow。
(示例)如果您想使用“我这次推荐A -site”的A-点链接。
“这次,我们建议一个站点。
”
用noindex拒绝
NOINDEX是一种元元素,当此描述不是时,爬虫将不会注册索引。无论其他网站是否链接到该页面,该页面都会完全从Google搜索结果中删除。
当您想从搜索结果本身而不是链接管理中消除显示时,请使用它。
请在“主题”部分中描述如下。
・如果您想阻止大多数搜索引擎的爬行者
・如果您想阻止Googlebot
<元元素上的评论>
注意!是否应该将其设置为索引?呢
请勿设置机器人。
如果在NOIndex设置页面上设置了robots.txt,则爬网可能无法识别NOIndex指令,而是其他页面的链接,将显示该页面。
我将解释为什么会发生这样的事情以及robots.txt的机制。
用Robots.txt垃圾
如何准备机器人.txt文件并将其上传到网站。像Nofollow一样,这是您不想爬行的页面的有效手段。
与拒绝遵循链接的nofollow不同,robots.txt是拒绝轨道本身作为特定路径或文件的一种方法。
因此,如果在识别NOIndex设置之前设置了robots.txt,则爬网将无法识别页面上设置的NOINDEX设置。
结果,它将继续从另一页的内部链接索引。
在这种情况下,警告“被robots.txt阻止,但在索引中注册”出现在搜索控制台上,因此Google识别NOINDEX设置(即使您搜索,该页面是页面。确认它没有出现之后)。
<官员:如何创建一个robots.txt文件>
但是,即使您设置了noindex或设置robots.txt,如果用户正在为抓取目标上的目标页面添加书签,则可以浏览该页面。
如果您不想被爬行,例如正在开发的页面,或者您不希望用户访问页面,请应用密码。
接下来,我们将介绍如何限制Crawler访问和用户访问权限。
拒绝.htaccess
.htaccess是一个可以配置和控制在目录上使用称为“ apache”的软件的文件。您可以设置一个重定向,使仅从特定的IP地址连接成为可能。其中之一是将ID和密码身份验证添加到基本身份验证网站。如果设置基本身份验证,则爬网将无法访问该站点。可以通过准备.htaccess文件并将其上传到服务器(例如robots.txt文件)来设置基本的身份验证设置。
如果您不想通过爬行者或用户,请设置基本身份验证。
<单击此处以获取基本身份验证的详细说明
*

SEO风格正在网站上免费诊断和咨询
这次,我解释了有关爬网措施的解释。 SEO措施不仅是内容的质量,而且是这样的技术SEO,因此让我们采取措施。
但是,这些技术部件具有更多的IT术语,并且可能很难学习和采取措施。在这种情况下,请咨询SEO风格。我们将从网站诊断中启动站点问题,并提出适当的解决方案。 <查询>













![[2022年5月的核心更新] Google宣布了2022年的第一个核心更新!](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/23628486_s-75x75.jpg)
![[站点运营商必须看到]是什么原因导致排名下降?如何发布罚款类型以及如何取消罚款类型?](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/4925517_s-75x75.jpeg)
![[2021年11月本地搜索更新]本地搜索更新](https://www.seostyle.net/esuio4587/wp-content/uploads/2021/12/5002701_s-1-75x75.jpeg)






