[Drop de classement SEO] Types et causes des erreurs de crawl
12 mai 2022 SEO technique , contre-mesures de rampe , mesures de référencement , mesures internes

Qu'est-ce que l'erreur de crawl?
Je pense que certaines personnes peuvent ne pas entendre grand-chose de parler des erreurs de rampe, donc je vais d'abord expliquer.
Une page où Googlebot, un robot Google, n'a pas pu ramper, c'est-à-dire une page qui n'a pas pu être confirmée.
Avez-vous déjà vu une telle page avec un moteur de recherche?
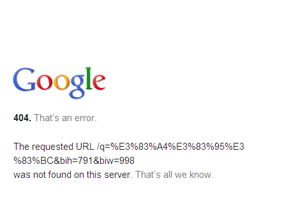
Il s'agit de l'état d'erreur de manche. Je vois souvent 404!
Il existe d'autres types, mais je vais expliquer plus tard.
Juste à cause de cette erreur de manche ne baisse pas, mais Google est "malveillant" même si vous n'avez pas l'intention de faire une grande quantité d'erreurs de manche.
Type d'erreur de crawl
Il existe deux principaux types d'erreurs de crawl.
・ Erreur du site… Le Crawler ne peut pas accéder au site à tout
・ Erreur d'URL… Dans le bogue du programme,
y a une page qui n'est pas dans un état où il y a une page, mais une page d'état qui ne le transmet pas.
Un message apparaît dans l'outil Webmaster, vous pouvez donc vérifier la cause en cliquant sur l'URL avec une erreur.
Cause principale
Il y a un code d'état pour afficher la cause.
Il existe plusieurs types, mais je vais prendre le code commun et les présenterai.
・ 404… il n'y a pas de page demandée
・ 403… Interdiction d'accès
・ 503… L'accès temporaire n'est pas possible
・ 400… Demande illégale
・ 408… Tempsion
En regardant cela, j'ai l'impression d'avoir fait quelque chose de mal, mais c'était un avertissement que "je suis une erreur, mais ça va?
" Ne l'effacez pas dans le noir parce qu'il y a une loi.
Comment éliminer les erreurs de chape
Il existe différentes façons de gérer les erreurs en fonction de la cause, mais cette fois, nous présenterons comment éliminer les erreurs 404 communes.
L'erreur 404 n'a pas de page pour une raison quelconque à partir de l'explication précédente.
La première chose que je doute en ce moment est: "changez-vous l'URL du site?"
Par exemple, supposons qu'un article de blog soit téléchargé une fois dans "20150420brog.html" et est indexé sur un robot. Cependant, après cela, quand j'ai pensé "Oh, j'ai fait une erreur dans le sort" et j'ai changé le nom en "20150420blog.html" et je l'ai téléchargé, lorsque j'ai accédé "20150420brog.html" à partir du moteur de recherche, cette page est une erreur 404.
Il y a une page, mais le nom a changé, il sera donc traité comme une page qui ne sera pas une page ... Dans un tel cas, je redirigerai bien et informerai Google qu'elle a changé de "0150420BLOG.HTML" à "20150420blog.html".











![[La mise à jour de base de mai 2022] Google annonce la première mise à jour de base en 2022!](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/23628486_s-75x75.jpg)
![[L'opérateur de site doit voir] Qu'est-ce qui a causé la baisse de classement? Comment libérer le type de pénalité et comment l'annuler?](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/4925517_s-75x75.jpeg)
![[Novembre 2021 Mise à jour de la recherche locale] Mise à jour de la recherche locale](https://www.seostyle.net/esuio4587/wp-content/uploads/2021/12/5002701_s-1-75x75.jpeg)






