Mécanisme de l'écran de classement de recherche
Avant l'explication du robot de robot, maintenons simplement le flux des informations sur Internet et les affichées.
Le mécanisme avec le classement du moteur de recherche est que le Crawler collecte toutes les informations sur Internet, les index (enregistrement de la base de données) et les données enregistrées sont avec un classement (évaluation des algorithmes). En d'autres termes, il est nécessaire de stocker diverses informations en tant qu'index (enregistrement de la base de données) pour être classé, et pour l'indexer nécessite une rampe. Le programme qui ramasse des informations s'appelle un robot. à quel point vous travaillez dur et créez du contenu , il ne sera pas affiché dans les résultats de recherche.
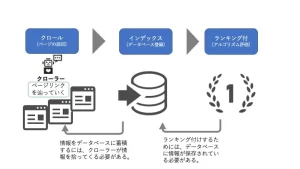
Que fait le Crawler?
Le Crawler effectue une "analyse (Perhaling)" lorsque vous atteignez la page.
"Analyse" signifie traitement des informations de la page afin que l'algorithme soit facile à comprendre et enregistre dans la base de données. Dans le cadre de cela, nous trouverons un lien dans la page et procéderons avec les pages les unes après les autres.
-L'objectif
de griffe de fichiers de la rampe est diversifié comme suit, et la plupart des informations sur le Web sont collectées par le robot.
・ Fichier HTML
・ Fichier CSS
・ Fichier JavaScript
・ Image
・ Flash
・ Le type PDF
-crawler
a également un type de robot, et des programmes sont disponibles pour chaque moteur de recherche. En plus de cela, il existe divers robots qui développent des services de chenilles.
Googlebot (Google)
, Bingbot (Bing exploité par Microsoft)
, Yahoo Slurp (Yahoo! Autre que le Japon)
, BaidUspider (site de recherche chinois Baidu)
, Yetibot (Corée du site de recherche majeure Naver)
L'importance de l'exploration
Bien qu'il existe une différence d'échelle entre chaque site, il y a des dizaines de millions de pages sur Internet. Dans de telles circonstances, le nombre de robots peut être patrouillé. Par conséquent, si vous jugez que les rampes ne sont pas nécessaires, la fréquence des rampes sera réduite pour empêcher les déchets.
・ Les sites dont les sites sont en permanence mis à jour ou
ont cessé de mettre à jour seront jugés qu'il n'y a pas besoin de rampes.
・ Il y a une demande de sites, et
même si la fréquence de mise à jour n'est pas si élevée, les sites utilisés par de nombreux utilisateurs sont correctement rampés.
Si vous vous concentrez sur les mesures de référencement, je pense que nous nous concentrons déjà sur les mises à jour continues des sites ci-dessus et la production de contenu solide. Alors, que dois-je faire pour faire craquer et index de la page créée? Pour ce faire, il est nécessaire d'améliorer le dynamisme. Le raccourcissement signifie que le robot est plus facile à trouver des pages et exprime le site Web pour faciliter le déchiffrement des Crawlers pour déchiffrer les informations sur le site Web.
Pour avoir un robot de robot une fréquence élevée,
je vais expliquer spécifiquement quelles pages et sites sont élevés.
・ En joignant le lien interne aux pages élevées connexes,
les pages liées sont liées aux pages connexes, afin que le robot peut être reconnu pour chaque page. À ce moment-là, en en faisant un nom de lien facile-pour comprendre, la pertinence avec le mot-clé est plus facile à comprendre.
・ Si l'URL est utilisée pour définir une liste de miettes de pain et que la hiérarchie des pages
est compliquée, ce sera un site qui sera difficile à comprendre pour le robot et l'efficacité sera réduite. Configurez un punk Slist pour faciliter le robot pour saisir la structure du site. <Cliquez ici pour le réglage de la liste des miettes de pain>
-Les pages importantes qui rendent la hiérarchie URL superficielle,
suivez le lien interne, il est donc plus facile que les pages avec des liens peu profonds soient diffusés au robot.
Si le lien devient plus profond, le robot peut prendre le temps de trouver la page.
・ Crawler, qui marque la configuration du texte,
ne comprend pas le contenu du texte comme nous lisons. Vous pouvez transmettre la configuration de la page en marquant la configuration de la page telle que les titres et les paragraphes avec une balise HTML.
HTML peut être défini sous forme de <nom d'élément attribut = "Attribut Value">,
et il est facile de comprendre si vous le remplacez par le robot, tel que "l'attribut du nom de l'élément est la valeur d'attribut".
Par exemple,

si
IMG (Image Embedded Element), SCR (attribut), Valeur d'attribut (URL de l'image utilisée) ou Alt la SCR (source d'information) d'IMG (Imaging) est "URL" et Alt (IMG). L'explication de l'élément).
Vous avez tendance à oublier de définir une balise alt qui transmet des images et des illustrations dans la page au robot. Mettons fermement les étiquettes fines.
< Cliquez ici pour rédiger des balises HTML >
・ Préparer des cartes de sites XML pour le robot de robot
Il existe deux types de sites de sites, des sitemaps HTML pour transmettre les informations du site de manière facile à comprendre et pour que les utilisateurs puissent facilement atteindre la page souhaitée. Il existe une carte de site XML qui transmet les informations nécessaires dans le robot de robot d'une manière facile à comprendre. En préparant une carte de site XML, vous
pouvez transmettre diverses informations sur le site au robot.
・ Dites la dernière date de mise à jour de la page
・ Faire la fréquence de mise à jour de la page
・ Dites la priorité à la page
・ Troller qui transmet l'existence de pages avec peu de liens internes,
si le site n'est pas mis à jour, il est rampé pour empêcher les déchets. J'ai parlé de la fréquence, mais en préparant une carte de site XML, vous pouvez transmettre correctement les informations de mise à jour.
▼ Article connexe
< à propos de la définition de la carte du site XML > < Plux recommandée -in >
Les grands sites à l'échelle nécessitent des mesures! À propos du budget d'exploration
Jusqu'à présent, nous avons expliqué l'importance des rampes, mais cela ne signifie pas que toutes les pages sont toutes rampées. Avez-vous déjà entendu le mot budgétaire du mot?
Un budget d'exploration est la limite supérieure d'un robot qui vous permet de patrouiller la page.
Budget = budget, mais cela ne devient pas confus si vous apprenez qu'il y a un nombre fixe à l'avance, comme un budget, comme budget. Si vous allez au-delà des budgets de rampe, les Crawlers ne pourront pas ramper la page du site cible, vous devez donc optimiser les rampes.
Cependant, il n'y a pas grand-chose à atteindre une telle limite supérieure, vous n'avez donc pas à vous soucier trop de ramper à l'exception de dizaines de milliers de pages.
Les cas suivants où Google devrait considérer la limite supérieure est le suivant.
・ Sites à grande échelle (1 million de pages ou plus), lorsque les mises à jour du contenu sont modérées (une fois par semaine)
・ Sites sur les moyens de taille moyenne ou plus (10 000 pages ou plus), le contenu est rapide (quotidiennement). S'il est modifié
, il est possible d'effectuer des recherches complexes comme les sites immobiliers et les sites de communication E, et si vous définissez des paramètres dans l'URL de chaque résultat de recherche, ou le numéro de produit uniquement en fonction du fonctionnement du site EC. Vous avez une grande quantité d'URL, vous devez faire attention si vous avez une URL distincte sur un site de smartphone et un site PC. Bien que le contenu de la page soit le même, il y a plusieurs URL, donc si vous ne les gérez pas, il y aura des problèmes qui ne seront pas rampés de manière stable sur la page que vous souhaitez évaluer.
Si vous voulez gérer les rampes et comment refuser
En plus de considérer les budgets de la crawl,
si vous souhaitez garder votre propre engagement, ou si vous souhaitez le garder comme un site à faible qualité, ou une page avec une faible pertinence pour le site.
Il est parfois préférable de refuser des rampes Pendant les tests ou lors de l'ajustement Veuillez vous référer à certaines des méthodes.
Gérer les unités de liaison avec nofollow
Nofollow est la valeur à définir si vous souhaitez éviter de suivre le lien lié. Recommandé lors de la prise d'un lien inutile en considération des budgets d'exploration.
Le nombre de liens spécifiques peut être effectué avec l'attribut rel de l'élément d'ancrage (un élément).
(Exemple) Si vous souhaitez utiliser le lien A-SITE de "Je recommande un -Site cette fois."
"Cette fois, nous recommandons un site."
Également, si vous voulez noter la page entière, vous pouvez le spécifier avec des éléments Meta.
Déchets avec noindex
NOINDEX est un type de méta-élément, et lorsque cette description n'est pas, le Crawler n'enregistre pas l'indice. Que les autres sites soient liés à cette page, la page est complètement supprimée des résultats de recherche Google.
Utilisez-le lorsque vous souhaitez éliminer l'affichage du résultat de la recherche lui-même, pas la gestion des liens.
Veuillez le décrire dans la section du sujet comme suit.
・ Si vous souhaitez bloquer le robot de la plupart des moteurs de recherche
・ Si vous souhaitez bloquer Googlebot
<Commentaire sur Meta Elements>
Remarque! Existe-t-il un cas où il devrait être indexé, même s'il aurait dû être réglé? !
Ne définissez pas le robots.txt, l'une des méthodes de rejet de griffes suivantes décrites sur la page de paramètre NOINDEX.
Si Robots.txt est défini sur la page NOINDEX SET, le Crawler peut ne pas reconnaître la directive NOINDEX, mais le lien des autres pages, la page sera affichée.
J'expliquerai pourquoi une telle chose se produit et le mécanisme des robots.txt.
Refus avec robots.txt
Comment préparer un fichier robots.txt et le télécharger sur le site. Comme Nofollow, c'est un moyen efficace pour les pages que vous ne voulez pas ramper.
Contrairement à Nofollow, qui refuse de suivre le lien, Robots.txt est une méthode pour refuser un robot lui-même pour un chemin ou un fichier spécifique.
Par conséquent, si vous définissez les robots.txt avant que les paramètres NOINDEX ne soient reconnus, le robot ne reconnaîtra pas les paramètres NOINDEX définis sur la page.
Par conséquent, il continuera d'être indexé à partir du lien interne d'une autre page.
Dans un tel cas, un avertissement que "a été bloqué par Robots.txt, mais enregistré dans l'index" apparaît sur la console de recherche, donc Google reconnaît le paramètre NOINDEX (même si vous recherchez, la page est la page. Vérifiez Robots.txt Après avoir confirmé qu'il ne sort pas).
<Official: Comment créer un fichier robots.txt >
Cependant, même si vous définissez NOINDEX ou définissez Robots.txt, si l'utilisateur est en signet de la page cible pour fonctionner sur le robot.
Si vous ne voulez pas être rampé, comme une page en cours de développement, ou si vous ne souhaitez pas que les utilisateurs accédent à la page, appliquez un mot de passe.
Ensuite, nous présenterons comment restreindre l'accès au robot et l'accès des utilisateurs.
Rejeter avec .htaccess
.htaccess est un fichier qui peut configurer et contrôler un serveur Web qui utilise le logiciel appelé "Apache" dans un répertoire. Vous pouvez définir une redirection, permettre de vous connecter uniquement à partir d'une adresse IP spécifique. L'un d'eux consiste à ajouter l'authentification d'identification et de mot de passe au site d'authentification de base. Si vous définissez l'authentification de base, le Crawler ne pourra pas accéder au site. Le paramètre d'authentification de base peut être défini en préparant le fichier .htaccess et en le téléchargeant sur le serveur, comme le fichier robots.txt.
Si vous ne souhaitez pas passer par le robot ou l'utilisateur, définissez l'authentification de base.
<Cliquez ici pour une explication détaillée de l'authentification de base
*

Le style SEO reçoit un diagnostic et une consultation gratuits sur le site
Cette fois, j'ai expliqué les mesures de rampe. Les mesures de référencement ne sont pas seulement la qualité du contenu, mais aussi ces SEO techniques techniques, alors prenons des mesures.
Cependant, ces parties techniques ont plus de termes informatiques, et il peut être difficile d'étudier et de prendre des mesures. Dans un tel cas, veuillez consulter le style SEO. Nous lancerons un problème de site à partir du diagnostic du site et proposerons une solution appropriée. <Demandes>













![[La mise à jour de base de mai 2022] Google annonce la première mise à jour de base en 2022!](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/23628486_s-75x75.jpg)
![[L'opérateur de site doit voir] Qu'est-ce qui a causé la baisse de classement? Comment libérer le type de pénalité et comment l'annuler?](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/4925517_s-75x75.jpeg)
![[Novembre 2021 Mise à jour de la recherche locale] Mise à jour de la recherche locale](https://www.seostyle.net/esuio4587/wp-content/uploads/2021/12/5002701_s-1-75x75.jpeg)






