Mecanismo de visualización de clasificación de búsqueda
Antes de la explicación del rastreador, simplemente mantengamos el flujo de la información en Internet y la mostrara.
El mecanismo con la clasificación del motor de búsqueda es que el rastreador recopila toda la información en Internet, los índices (registro de la base de datos), y los datos registrados son con una clasificación (evaluación de algoritmo). En otras palabras, es necesario almacenar diversas información como un índice (registro de la base de datos) para ser clasificado, y para indexarla requiere rastrear. El programa que recoge información se llama rastreador. cuánto funcione y cree contenido , no se mostrará en los resultados de búsqueda.
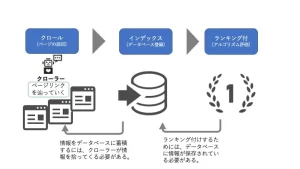
¿Qué está haciendo el rastreador?
El rastreador realiza un "análisis (perhaling)" cuando llega a la página.
"Análisis" significa procesar la información de la página para que el algoritmo sea fácil de entender y registrarse en la base de datos. Como parte de eso, encontraremos un enlace en la página y continuaremos con las páginas una tras otra.
-El
objetivo de clavación del rastreo es diverso de la siguiente manera, y el rastreador recopila la mayoría de la información en la web.
・ Archivo HTML
・ Archivo CSS
・ Archivo JavaScript
・ Imagen
・ Flash
・ El tipo PDF
-Crawler
también tiene un tipo de rastreador, y los programas están disponibles para cada motor de búsqueda. Además de esto, hay varios rastreadores que están desarrollando servicios de rastreadores.
Googlebot (Google)
, Bingbot (Bing operado por Microsoft)
, Yahoo Slurp (Yahoo! aparte de Japón)
, BaidUspider (sitio de búsqueda chino Baidu)
, Yetibot (Corea Major Search Site Naver)
La importancia de la rastreabilidad en las medidas de rastreo
Aunque hay una diferencia en la escala entre cada sitio, hay decenas de millones de páginas en Internet. En tales circunstancias, el número de rastreadores puede patrullar. Por lo tanto, si juzga que los rastreos no son necesarios, la frecuencia de los rastreos se reducirá para prevenir los desechos.
・ Los sitios cuyos sitios se actualizan continuamente o
han dejado de actualizar se juzgarán que no hay necesidad de rastrear.
・ Hay una demanda de sitios, e
incluso si la frecuencia de actualización no es tan alta, los sitios utilizados por muchos usuarios se rastrean correctamente.
Si se está centrando en las medidas de SEO, creo que ya nos estamos centrando en las actualizaciones continuas de los sitios anteriores y la producción de contenido sólido. Entonces, ¿qué debo hacer para obtener el rastreo y el índice de la página creados? Para hacerlo, es necesario mejorar la rastreabilidad. La capacidad de rastreo significa que el rastreador es más fácil encontrar páginas y expresa el sitio web para que sea más fácil para los rastreadores descifrar la información en el sitio web.
Para tener un rastreador de alta frecuencia,
explicaré específicamente qué páginas y sitios son altos.
・ Al adjuntar el enlace interno a las páginas altas relacionadas,
las páginas vinculadas están vinculadas a las páginas relacionadas, de modo que el rastreador pueda ser reconocido para cada página. En ese momento, al hacer que sea un nombre de enlace fácil de entender, la relevancia con la palabra clave es más fácil de entender.
・ Si la URL se usa para establecer una lista de migas de pan y la jerarquía de la página
es complicada, será un sitio que será difícil para Crawler de comprender, y la eficiencia se reducirá. Configure una cubierta punk para facilitar que el rastreador capte la estructura del sitio. <Haga clic aquí para ver la configuración de la lista de crujiones de pan>
-Las páginas importantes que hacen que la jerarquía de URL sea superficial,
siga el enlace interno, por lo que es más fácil para las páginas con enlaces poco profundos que circulan al rastreador.
Si el enlace se vuelve más profundo, el rastreador puede tomarse el tiempo para encontrar la página.
・ Crawler, que marca la configuración del texto,
no comprende el contenido del texto mientras estamos leyendo. Puede transmitir la configuración de la página marcando la configuración de la página, como encabezados y párrafos con una etiqueta HTML.
HTML se puede configurar como <name de elemento attribute = "valor de atributo">,
y es fácil de entender si lo reemplaza con el rastreador, como "el atributo del nombre del elemento es el valor del atributo".
Por ejemplo,

si
IMG (elemento incrustado de imagen), SCR (atributo), valor de atributo (URL de la imagen utilizada) o Alt el SCR (fuente de información) de IMG (imágenes) es "URL" e ALT (IMG). La explicación del elemento).
Tiendes a olvidar establecer una etiqueta alternativa que transmite imágenes e ilustraciones en la página al rastreador. Pongamos las etiquetas finas con firmeza.
< Haga clic aquí para ver cómo escribir etiquetas HTML >
・ Preparación de mapas del sitio XML para Crawler
Hay dos tipos de mapas del sitio, Sitemaps HTML para transmitir la información del sitio de una manera fácil de entender para que los usuarios puedan comunicarse fácilmente con la página deseada. Hay un mapa del sitio XML que transmite la información necesaria en el rastreador de una manera fácil de entender. Al preparar un mapa del sitio XML,
puede transmitir varias información del sitio al rastreador.
・ Dice la última fecha de actualización de la página
・ Haga la frecuencia de actualización de la página
・ Diga la prioridad a la página
・ Troller que transmite la existencia de páginas con pocos enlaces internos,
si el sitio no está actualizado, está arrastrando los desechos. Hablé sobre la frecuencia, pero al preparar un mapa del sitio XML, puede transmitir la información de actualización correctamente.
▼ Artículo relacionado
< Acerca de la configuración del mapa del sitio XML > < enchufe recomendado -in >
¡Los sitios a gran escala requieren medidas! Sobre el presupuesto de rastreo
Hasta ahora, hemos explicado la importancia de los rastreos, pero eso no significa que todas las páginas estén rastadas. ¿Alguna vez has escuchado el presupuesto de Word Crawl?
Un presupuesto de rastreo es el límite superior de un rastreador que le permite patrullar la página.
Presupuesto = Presupuesto, pero no se confunde si se entera de que hay un número fijo por adelantado, como un presupuesto, como un presupuesto. Si va más allá de los presupuestos de rastreo, los rastreadores no podrán rastrear la página del sitio de destino, por lo que debe optimizar los rastreo.
Sin embargo, no hay mucho que alcanzar un límite superior de este tipo, por lo que no necesita preocuparse demasiado por gatear, excepto por decenas de miles de páginas.
Los siguientes casos en los que Google debe considerar el límite superior es el siguiente.
・ Sitios a gran escala (1 millón de páginas o más), cuando las actualizaciones de contenido son moderadas (una vez a la semana)
・ Sitios sobre mediano o más (10,000 páginas o más), el contenido es rápido (a diario). Si se cambia
, es posible realizar búsquedas complejas como sitios inmobiliarios y sitios de comercio electrónico, y si establece parámetros en la URL de cada resultado de la búsqueda, o el número de producto solo dependiendo del funcionamiento del sitio de la CE. Tiene una gran cantidad de URL, debe tener cuidado si tiene una URL separada en el sitio de un teléfono inteligente y un sitio de PC. Aunque el contenido de la página es el mismo, hay múltiples URL, por lo que si no las administra, habrá problemas que no se arrastran de manera estable en la página que desea evaluar.
Si desea administrar rastreos y cómo rechazar
Además de considerar los presupuestos de rastreo,
si desea mantener su propio compromiso, o si desea mantenerlo como un sitio que sea de baja calidad, o una página con baja relevancia para el sitio.
A veces es mejor rechazar los rastreo durante la prueba o al ajustar Consulte algunos de los métodos.
Administrar unidades de enlace con nofollow
Nofollow es el valor para establecer si desea evitar seguir el enlace vinculado. Recomendado al tomar un vínculo innecesario en consideración de los presupuestos de rastreo.
Nofollow de enlaces específicos se puede hacer con el atributo REL del elemento de anclaje (un elemento).
(Ejemplo) Si desea usar el enlace A -Site de "Recomiendo un sitio esta vez".
"Esta vez, recomendamos un sitio"
.
Basura con noindex
Noindex es un tipo de meta elemento, y cuando esta descripción no lo es, el rastreador no registra el índice. Independientemente de si otros sitios están vinculados a esa página, la página está completamente eliminada de los resultados de búsqueda de Google.
Úselo cuando desee eliminar la pantalla del resultado de la búsqueda en sí, no la gestión de enlaces.
Descríbalo en la sección de la materia de la siguiente manera.
・ Si desea bloquear al rastreador de la mayoría de los motores de búsqueda
・ Si quieres bloquear Googlebot
<Comentario sobre Meta Elementos>
¡NOTA! ¿Hay algún caso en el que debería indexarse, aunque debería haberse establecido? !
No establezca el robots.txt, uno de los siguientes métodos de rechazo de garra descritos en la página de configuración noindex.
Si Robots.txt se establece en la página de configuración de noindex, el rastreador puede no reconocer la directiva noindex, pero el enlace de otras páginas, la página se mostrará.
Explicaré por qué sucede tal cosa y el mecanismo de robots.txt.
Rechazo con robots.txt
Cómo preparar un archivo robots.txt y cargarlo en el sitio. Al igual que nofollow, es un medio efectivo para las páginas que no desea gatear.
A diferencia de Nofollow, que se niega a seguir el enlace, Robots.txt es un método para rechazar un rastreador en sí para una ruta o archivo específico.
Por lo tanto, si establece el robots.txt antes de reconocer la configuración de noindex, el rastreador no reconocerá la configuración noindex establecida en la página.
Como resultado, continuará indexado desde el enlace interno de otra página.
En tal caso, una advertencia que "fue bloqueada por robots.txt, pero registrada en el índice" aparece en la consola de búsqueda, por lo que Google reconoce la configuración noindex (incluso si busca, la página es la página. Compruebe robots.txt. Después de confirmar que no sale).
<Oficial: cómo crear un archivo robots.txt >
Sin embargo, incluso si configura noindex o configura robots.txt, si el usuario está marcando la página de destino para que funcione en el rastreador.
Si no desea que se rastree, como una página en desarrollo, o si no desea que los usuarios accedan a la página, aplique una contraseña.
A continuación, presentaremos cómo restringir el acceso de los rastreadores y el acceso al usuario.
Rechazar con .htaccess
.htaccess es un archivo que puede configurar y controlar un servidor web que usa el software llamado "Apache" en un directorio. Puede establecer una redirección, hacer posible conectarse solo desde una dirección IP específica. Uno de ellos es agregar autenticación de identificación y contraseña al sitio de autenticación básica. Si establece la autenticación básica, el rastreador no podrá acceder al sitio. La configuración de autenticación básica se puede establecer preparando el archivo .htaccess y cargándolo en el servidor, como el archivo robots.txt.
Si no desea pasar por el rastreador o el usuario, configure la autenticación básica.
<Haga clic aquí para obtener una explicación detallada de la autenticación básica
*

SEO Style está recibiendo diagnóstico y consulta gratuitos en el sitio
Esta vez, expliqué sobre las medidas de rastreo. Las medidas de SEO no son solo la calidad del contenido, sino también tales SEO técnicos técnicos, así que tomemos medidas.
Sin embargo, estas partes técnicas tienen más términos de TI, y puede ser difícil estudiar y tomar medidas. En tal caso, consulte el estilo de SEO. Lanzaremos un problema del sitio desde el diagnóstico del sitio y propondremos una solución adecuada. <Consultas>













![[La actualización central de mayo de 2022] Google anuncia la primera actualización del núcleo en 2022!](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/23628486_s-75x75.jpg)
![[El operador del sitio debe ver] ¿Qué causó la caída de clasificación? ¿Cómo lanzar el tipo de penalización y cómo cancelarlo?](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/4925517_s-75x75.jpeg)
![[Noviembre de 2021 Actualización de búsqueda local] Actualización de búsqueda local](https://www.seostyle.net/esuio4587/wp-content/uploads/2021/12/5002701_s-1-75x75.jpeg)






