Mechanism of search ranking display
Before the crawler explanation, let's simply hold down the flow of the information on the Internet and displayed it.
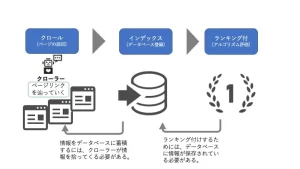
The mechanism with the ranking of the search engine is that the crawler collects all information on the Internet, indexes (database registration), and the registered data is with a ranking (algorithm evaluation). In other words, it is necessary to store various information as an index (database registration) to be ranked, and to index it requires crawl. The program that picks up information is called a crawler. how hard you work and create content , it will not be displayed in the search results.
What is the crawler doing?
The crawler performs an "analysis (perhaling)" when you reach the page.
"Analysis" means processing the page information so that the algorithm is easy to understand and registers in the database. As part of that, we will find a link in the page and proceed with the pages one after another.
-The file
clawing target of the crawling is diverse as follows, and most information on the web is collected by the crawler.
・ HTML file
・ CSS file
・ JavaScript file
・ Image
・ Flash
・ PDF
-Crawler type
also has a type of crawler, and programs are available for each search engine. In addition to this, there are various crawlers that are developing crawler services.
GoogleBot (Google)
, BingBot (Bing operated by Microsoft)
, Yahoo Slurp (Yahoo! other than Japan)
, BAIDUSPIDER (Chinese Search Site Baidu)
, YETIBOT (Korea Major Search Site NAVER)
The importance of crawlerability in crawl measures
Although there is a difference in scale between each site, there are tens of millions of pages on the Internet. Under such circumstances, the number of crawlers can be patroled. Therefore, if you judge that crawls are not necessary, the frequency of crawls will be reduced to prevent waste.
・ Sites whose sites are continuously updated or
have stopped updating will be judged that there is no need for crawls.
・ There is a demand for sites, and
even if the update frequency is not so high, sites used by many users are properly crawled.
If you are focusing on SEO measures, I think that we are already focusing on continuous updates of the above sites and the production of solid content. So what should I do to get the created page crawl and index? To do so, it is necessary to improve the crawlerability. Crawlability means that the crawler is easier to find pages and expresses the website to make it easier for Crawlers to decipher the information on the website.
To have a crawler a high frequency,
I will specifically explain what pages and sites are high.
・ By attaching the internal link to the related high pages,
the linked pages are linked to the related pages, so that the crawler can be recognized for each page. At that time, by making it an easy -to -understand link name, the relevance with the keyword is easier to understand.
・ If the URL is used to set a bread crumbs list and the page hierarchy
is complicated, it will be a site that will be difficult for crawler to understand, and the efficiency will be reduced. Set up a punk slist to make it easier for the crawler to grasp the structure of the site. <Click here for the setting of the bread crumbs list>
-The important pages that make the URL hierarchy shallow,
follow the internal link, so it is easier for the pages with shallow links to be circulated to the crawler.
If the link becomes deeper, the crawler may take the time to find the page.
・ Crawler, which marks up the text configuration,
does not understand the contents of the text as we are reading. You can convey the page configuration by marking up the configuration of the page such as headings and paragraphs with an HTML tag.
HTML can be set as <element name attribute = "attribute value">,
and it is easy to understand if you replace it with the crawler, such as "the attribute of the element name is the attribute value".
For example,

if
IMG (image embedded element), SCR (attribute), attribute value (URL of the image used), or alt the SCR (information source) of IMG (imaging) is "URL" and Alt (Img). The explanation of the element).
You tend to forget to set an ALT tag that conveys images and illustrations in the page to the crawler. Let's put in the fine tags firmly.
< Click here for how to write HTML tags >
・ Preparing XML site maps for crawler
There are two types of site maps, HTML sitemaps to convey the site information in an easy -to -understand manner so that users can easily reach the desired page. There is an XML site map that conveys the necessary information in the crawler in an easy -to -understand manner. By preparing an XML site map, you
can convey various site information to the crawler.
・ Tell the last update date of the page
・ Make the page update frequency
・ Say the priority to the page
・ Troller that conveys the existence of pages with few internal links,
if the site is not updated, it is crawl to prevent waste. I talked about the frequency, but by preparing an XML site map, you can convey the update information properly.
▼ Related article
< About setting XML site map > < Recommended plug -in >
Large -scale sites require measures! About crawl budget
Until now, we have explained the importance of crawls, but it does not mean that all pages are all crawled. Have you ever heard the word crawl budget?
A crawl budget is the upper limit of a crawler that allows you to patrol the page.
Budget = budget, but it doesn't get confused if you learn that there is a fixed number in advance, like a budget, as a budget. If you go beyond crawl budgets, crawlers will not be able to crawl the target site page, so you need to optimize crawls.
However, there is not much to reach such an upper limit, so you do not need to worry too much about crawling except for tens of thousands of pages.
The following cases where Google should consider the upper limit is as follows.
・ Large -scale sites (1 million pages or more), when the content updates are moderate (once a week)
・ Sites over medium -sized or more (10,000 pages or more), the content is rapid (on a daily basis). If it is changed
, it is possible to perform complex searches like real estate sites and e -commerce sites, and if you set parameters in the URL of each search result, or the product number only depending on the operation of the EC site. If you have a large amount of URL, you need to be careful if you have a separate URL on a smartphone site and a PC site. Although the page content is the same, there are multiple URLs, so if you do not manage them, there will be problems that are not stably crawled on the page you want to evaluate.
If you want to manage crawls and how to refuse
In addition to considering crawl budgets,
if you want to keep your own commitment, or if you want to keep it as a site that is low -quality, or a page with low relevance to the site.
Sometimes it is better to refuse crawls during testing or when adjusting Please refer to some of the methods.
Manage link units with nofollow
Nofollow is the value to set if you want to avoid following the linked link. Recommended when taking a unnecessary link in consideration of crawl budgets.
Nofollow of specific links can be made with the REL attribute of the anchor element (A element).
(Example) If you want to use the A -site link of "I recommend A -site this time."
"This time, we recommend A -site."
Also, if you want to nofollow the entire page, you can specify it with META elements.
Refuse with noindex
Noindex is a type of meta element, and when this description is not, the crawler does not register index. Regardless of whether other sites are linked to that page, the page is completely deleted from Google Search results.
Use it when you want to eliminate the display from the search result itself, not the link management.
Please describe it in the subject section section as follows.
・ If you want to block the crawler of most search engines
・ If you want to block GoogleBot
<Commentary on Meta elements>
Note! Is there a case where it should be indexed, even though it should have been set? !
Do not set the Robots.txt, one of the next claw rejection methods described on the Noindex setting page.
If robots.txt is set on the Noindex set page, the crawler may not recognize the noindex directive, but the link from other pages, the page will be displayed.
I will explain why such a thing happens and the mechanism of Robots.txt.
Refuse with robots.txt
How to prepare a Robots.txt file and upload it to the site. Like Nofollow, it is an effective means for pages that you do not want to crawl.
Unlike Nofollow, which refuses to follow the link, Robots.txt is a method of refusing a crawler itself for a specific path or file.
Therefore, if you set the Robots.txt before the Noindex settings are recognized, the crawler will not recognize the NOINDEX settings set on the page.
As a result, it will continue to be indexed from the internal link of another page.
In such a case, a warning that "was blocked by robots.txt, but registered in the index" appears on the search console, so Google recognizes the NOINDEX setting (even if you search, the page is the page. Check Robots.txt after confirming that it doesn't come out).
<Official: How to create a Robots.txt file >
However, even if you set noindex or set Robots.txt, if the user is bookmarking the target page to work on the crawler. , You can browse the page.
If you do not want to be crawled, such as a page under development, or if you do not want users to access the page, apply a password.
Next, we will introduce how to restrict crawler access and user access.
Reject with .htaccess
.htaccess is a file that can configure and control a web server that uses the software called "apache" on a directory. You can set a redirect, make it possible to connect only from a specific IP address. One of them is to add ID and password authentication to the Basic authentication site. If you set Basic authentication, the crawler will not be able to access the site. The BASIC authentication setting can be set by preparing the .htaccess file and uploading it to the server, like the Robots.txt file.
If you do not want to pass through the crawler or user, set the Basic authentication.
<Click here for detailed explanation of Basic authentication
*

SEO STYLE is receiving free diagnosis and consultation on the site
This time, I explained about crawl measures. SEO measures are not only the quality of the content, but also such technical technical SEOs, so let's take measures.
However, these technical parts have more IT terms, and it may be difficult to study and take measures. In such a case, please consult SEO STYLE. We will launch a site problem from the site diagnosis and propose an appropriate solution. <Inquiries>













![[THE May 2022 Core Update] Google announces the first core update in 2022!](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/23628486_s-75x75.jpg)
![[Site operator must see] What caused the ranking drop? How to release the penalty type and how to cancel it?](https://www.seostyle.net/esuio4587/wp-content/uploads/2022/05/4925517_s-75x75.jpeg)
![[November 2021 Local Search Update] Local search update](https://www.seostyle.net/esuio4587/wp-content/uploads/2021/12/5002701_s-1-75x75.jpeg)






